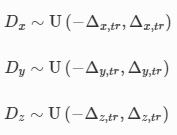To image, or not to image: class-specific diffractive cameras with all-optical erasure of undesired objects
Bijie Bai, Yi Luo, Tianyi Gan, Jingtian Hu, Yuhang Li, Yifan Zhao, Deniz Mengu, Mona Jarrahi & Aydogan Ozcan
Privacy protection is a growing concern in the digital era, with machine vision techniques widely used throughout public and private settings. Existing methods address this growing problem by, e.g., encrypting camera images or obscuring/blurring the imaged information through digital algorithms. Here, we demonstrate a camera design that performs class-specific imaging of target objects with instantaneous all-optical erasure of other classes of objects. This diffractive camera consists of transmissive surfaces structured using deep learning to perform selective imaging of target classes of objects positioned at its input field-of-view. After their fabrication, the thin diffractive layers collectively perform optical mode filtering to accurately form images of the objects that belong to a target data class or group of classes, while instantaneously erasing objects of the other data classes at the output field-of-view. Using the same framework, we also demonstrate the design of class-specific permutation and class-specific linear transformation cameras, where the objects of a target data class are pixel-wise permuted or linearly transformed following an arbitrarily selected transformation matrix for all-optical class-specific encryption, while the other classes of objects are irreversibly erased from the output image. The success of class-specific diffractive cameras was experimentally demonstrated using terahertz (THz) waves and 3D-printed diffractive layers that selectively imaged only one class of the MNIST handwritten digit dataset, all-optically erasing the other handwritten digits. This diffractive camera design can be scaled to different parts of the electromagnetic spectrum, including, e.g., the visible and infrared wavelengths, to provide transformative opportunities for privacy-preserving digital cameras and task-specific data-efficient imaging.
We kindly thank the researchers at University of California for this collaboration, and for sharing the results obtained with their system.

Introduction
Digital cameras and computer vision techniques are ubiquitous in modern society. Over the past few decades, computer vision-assisted applications have been adapted massively in a wide range of fields [1,2,3], such as video surveillance [4, 5], autonomous driving assistance [6, 7], medical imaging [8], facial recognition, and body motion tracking [9, 10]. With the comprehensive deployment of digital cameras in workspaces and public areas, a growing concern for privacy has emerged due to the tremendous amount of image data being collected continuously [11,12,13,14]. Some commonly used methods address this concern by applying post-processing algorithms to conceal sensitive information from the acquired images [15]. Following the computer vision-aided detection of the sensitive content, traditional image redaction algorithms, such as image blurring [16, 17], encryption [18, 19], and image inpainting [20, 21] are performed to secure private information such as human faces, plate numbers, or background objects. In recent years, deep learning techniques have further strengthened these algorithmic privacy preservation methods in terms of their robustness and speed [22,23,24]. Despite the success of these software-based privacy protection techniques, there exists an intrinsic risk of raw data exposure given the fact that the subsequent image processing is executed after the raw data recording/digitization and transmission, especially when the required digital processing is performed on a remote device, e.g., a cloud-based server.
Another set of solutions to such privacy concerns can be implemented at the hardware/board level, in which the data processing happens right after the digital quantization of an image, but before its transmission. Such solutions protect privacy by performing in-situ image modifications using camera-integrated online processing modules. For instance, by embedding a digital signal processor (DSP) or Trusted Platform Module (TPM) into a smart camera, the sensitive information can be encrypted or deidentified [25,26,27]. These camera integration solutions provide an additional layer of protection against potential attacks during the data transmission stage; however, they do not completely resolve privacy concerns as the original information is already captured digitally, and adversarial attacks can happen right after the camera’s digital quantization.
Implementing these image redaction algorithms or embedded DSPs for privacy protection also creates some environmental impact as a compromise. To support the computation/processing of massive amounts of visual data being generated every day [28], i.e., billions of images and millions of hours of videos, the demand for digital computing power and data storage space rapidly increases, posing a major challenge for sustainability [29,30,31,32].
Intervening into the light propagation and image formation stage and passively enforcing privacy before the image digitization can potentially provide more desired solutions to both of these challenges outlined earlier. For example, some of the existing works use customized optics or sensor read-out circuits to modify the image formation models, so that the sensor only captures low-resolution images of the scene and, therefore, the identifying information can be concealed [33,34,35]. Such methods sacrifice the image quality of the entire sample field-of-view (FOV) for privacy preservation, and therefore, a delicate balance between the final image quality and privacy preservation exists; a change in this balance for different objects can jeopardize imaging performance or privacy. Furthermore, degrading the image quality of the entire FOV limits the applicable downstream tasks to low-resolution operations such as human pose estimation. In fact, sacrificing the entire image quality can be unacceptable under some circumstances such as e.g., in autonomous driving. Additionally, since these methods establish a blurred or low-resolution pixel-to-pixel mapping between the input scene and the output image, the original information of the samples can be potentially retrieved via digital inverse models, using e.g., blind image deconvolution or estimation of the inherent point-spread function.
Here, we present a new camera design using diffractive computing, which images the target types/classes of objects with high fidelity, while all-optically and instantaneously erasing other types of objects at its output (Fig. 1). This computational camera processes the optical modes that carry the sample information using successive diffractive layers optimized through deep learning by minimizing a training loss function customized for class-specific imaging. After the training phase, these diffractive layers are fabricated and assembled together in 3D, forming a computational imager between an input FOV and an output plane. This camera design is not based on a standard point-spread function, and instead the 3D-assembled diffractive layers collectively act as an optical mode filter that is statistically optimized to pass through the major modes of the target classes of objects, while filtering and scattering out the major representative modes of the other classes of objects (learned through the data-driven training process). As a result, when passing through the diffractive camera, the input objects from the target classes form clear images at the output plane, while the other classes of input objects are all-optically erased, forming non-informative patterns similar to background noise, with lower light intensity. Since all the spatial information of non-target object classes is instantaneously erased through light diffraction within a thin diffractive volume, their direct or low-resolution images are never recorded at the image plane, and this feature can be used to reduce the image storage and transmission load of the camera. Except for the illumination light, this object class-specific camera design does not utilize external computing power and is entirely based on passive transmissive layers, providing a highly power-efficient solution to task-specific and privacy-preserving imaging.
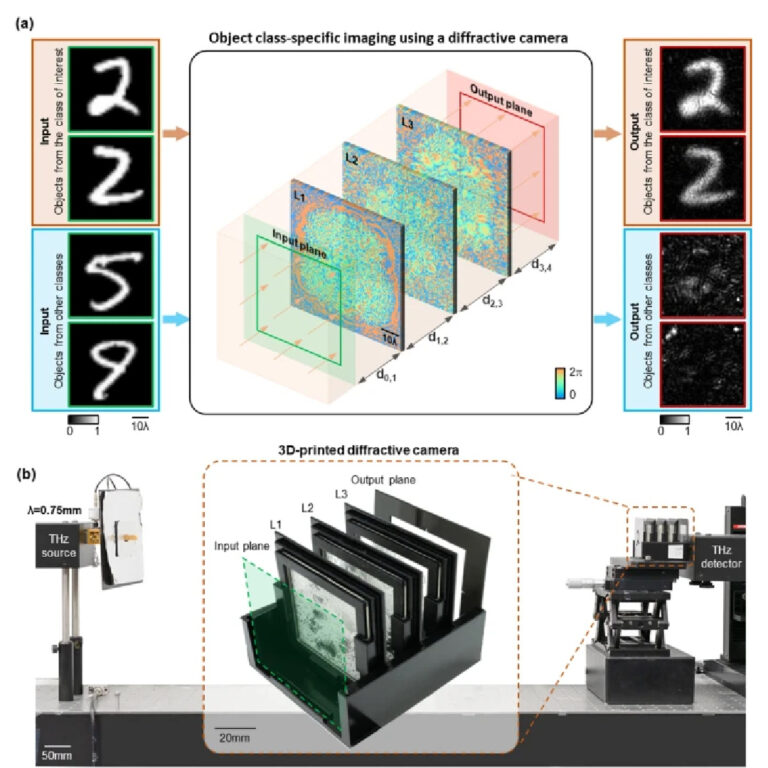
Object class-specific imaging using a diffractive camera. a Illustration of a three-layer diffractive camera trained to perform object class-specific imaging with instantaneous all-optical erasure of the other classes of objects at its output FOV. b The experimental setup for the diffractive camera testing using coherent THz illumination
We experimentally demonstrated the success of this new class-specific camera design using THz radiation and 3D-printed diffractive layers that were assembled together (Fig. 1) to specifically and selectively image only one data class of the MNIST handwritten digit database [36], while all-optically rejecting the images of all the other handwritten digits at its output FOV. Despite the random variations observed in handwritten digits (from human to human), our analysis revealed that any arbitrary handwritten digit/class or group of digits could be selected as the target, preserving the same all-optical rejection/erasure capability for the remaining classes of handwritten digits. Besides handwritten digits, we also showed that the same framework can be generalized to class-specific imaging and erasure of more complicated objects, such as some fashion products [37]. Additionally, we demonstrated class-specific imaging of input FOVs with multiple objects simultaneously present, where only the objects that belong to the target class were imaged at the output plane, while the rest were all-optically erased. Furthermore, this class-specific camera design was shown to be robust to variations in the input illumination intensity and the position of the input objects. Apart from direct imaging of the target objects from specific data classes, we further demonstrated that this diffractive imaging framework can be used to design class-specific permutation and class-specific linear transformation cameras that output pixel-wise permuted or linearly transformed images (following an arbitrarily selected image transformation matrix) of the target class of objects, while all-optically erasing other types of objects at the output FOV—performing class-specific encryption all-optically.
The teachings of this diffractive camera design can inspire future imaging systems that consume orders of magnitude less computing and transmission power as well as less data storage, helping with our global need for task-specific, data-efficient and privacy-aware modern imaging systems.

Results
Class-specific imaging using diffractive cameras
We first numerically demonstrate the class-specific camera design using the MNIST handwritten digit dataset, to selectively image handwritten digit ‘2’ (the object class of interest) while instantaneously erasing the other handwritten digits. As illustrated in Fig. 2a, a three-layer diffractive imager with phase-only modulation layers was trained under an illumination wavelength of λ. Each diffractive layer contains 120 × 120 trainable transmission phase coefficients (i.e., diffractive features/neurons), each with a size of ~ 0.53λ. The axial distance between the input/sample plane and the first diffractive layer, between any two consecutive diffractive layers, and between the last diffractive layer and the output plane were all set to ~ 26.7λ. The phase modulation values of the diffractive neurons at each transmissive layer were iteratively updated using a stochastic gradient-descent-based algorithm to minimize a customized loss function, enabling object class-specific imaging. For the data class of interest, the training loss terms included the normalized mean square error (NMSE) and the negative Pearson Correlation Coefficient (PCC) [38] between the output image and the input, aiming to optimize the image fidelity at the output plane for the correct class of objects. For all the other classes of objects (to be all-optically erased), we penalized the statistical similarity between the output image and the input object (see “Methods” section for details). This well-balanced training loss function enabled the output images from the non-target classes of objects (i.e., the handwritten digits 0, 1, 3–9) to be all-optically erased at the output FOV, forming speckle-like background patterns with lower average intensity, whereas all the input objects of the target data class (i.e., handwritten examples of digit 2) formed high-quality images at the output plane. The resulting diffractive layers that are learned through this data-driven training process are reported in Fig. 2b, which collectively function as a spatial mode filter that is data class-specific.
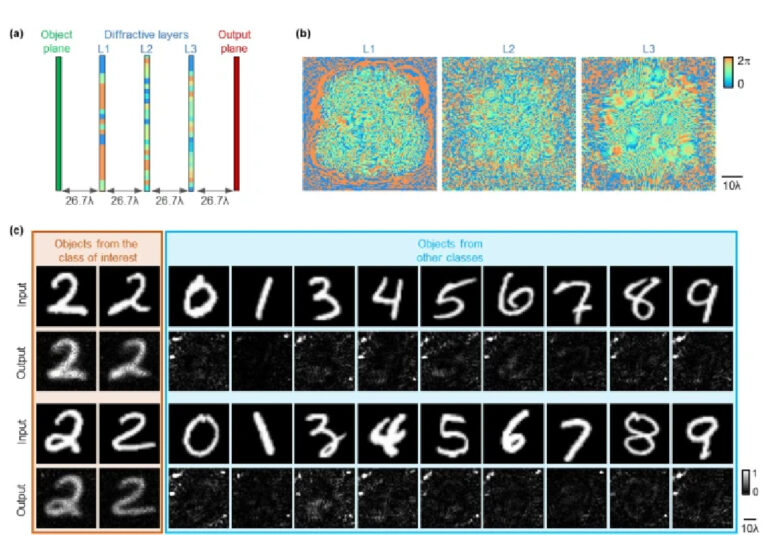
Design schematic and blind testing results of the class-specific diffractive camera. a The physical layout of the three-layer diffractive camera design. b Phase modulation patterns of the converged diffractive layers of the camera. c The blind testing results of the diffractive camera. The output images were normalized using the same constant for visualization
After its training, we numerically tested this diffractive camera design using 10,000 MNIST test digits, which were not used during the training process. Figure 2c reports some examples of the blind testing output of the trained diffractive imager and the corresponding input objects. These results demonstrate that the diffractive camera learned to selectively image the input objects that belong to the target data class, even if they have statistically diverse styles due to the varying nature of human handwriting. As desired, the diffractive camera generates unrecognizable noise-like patterns for the input objects from all the other data classes, all-optically erasing their information at its output plane. Stated differently, the image formation is intervened at the coherent wave propagation stage for the undesired data classes, where the characteristic optical modes that statistically represent the input objects of these non-target data classes are scattered out of the output FOV of our diffractive camera.
Importantly, this diffractive camera is not based on a standard point-spread function-based pixel-to-pixel mapping between the input and output FOVs, and therefore, it does not automatically result in signals within the output FOV for the transmitting input pixels that statistically overlap with the objects from the target data class. For example, the handwritten digits ‘3’ and ‘8’ in Fig. 2c were completely erased at the output FOV, regardless of the considerable amount of common (transmitting) pixels that they statistically share with the handwritten digit ‘2’. Instead of developing a spatially-invariant point-spread function, our designed diffractive camera statistically learned the characteristic optical modes possessed by different training examples, to converge as an optical mode filter, where the main modes that represent the target class of objects can pass through with minimum distortion of their relative phase and amplitude profiles, whereas the spatial information carried by the characteristic optical modes of the other data classes were scattered out. The deep learning-based optimization using the training images/examples is the key for the diffractive camera to statistically learn which optical modes must be filtered out and which group of modes needs to pass through the diffractive layers so that the output images accurately represent the spatial features of the input objects for the correct data class. As detailed in “Methods” section, the training loss function and its penalty terms for the target data class and the other classes are crucial for achieving this performance.
In addition to these results summarized in Fig. 2, the same class-specific imaging system can also be adapted to selectively image input objects of other data classes by simply re-dividing the training image dataset into desired/target vs. unwanted classes of objects. To demonstrate this, we show different diffractive camera designs in Additional file 1: Fig. S1, where the same class-specific performance was achieved for the selective imaging of e.g., handwritten test objects from digits ‘5’ or ‘7’, while all-optically erasing the other data classes at the output FOV. Even more remarkable, the diffractive camera design can also be optimized to selectively image a desired group of data classes, while still rejecting the objects of the other data classes. For example, Additional file 1: Fig. S1 reports a diffractive camera that successfully imaged handwritten test objects belonging to digits ‘2’, ‘5’, and ‘7’ (defining the target group of data classes), while erasing all the other handwritten digits all-optically. Stated differently, the diffractive camera was in this case optimized to selectively image three different data classes in the same design, while successfully filtering out the remaining data classes at its output FOV (see Additional file 1: Fig. S1).
To further demonstrate the success of the presented class-specific diffractive camera design for processing more complicated objects, we extended it to specifically image only one class of fashion products [37] (i.e., trousers). As shown in Additional file 1: Fig. S2, a seven-layer diffractive camera was designed to achieve class-specific imaging of trousers within the Fashion MNIST dataset [37], while all-optically erasing/rejecting four other classes of the fashion products (i.e., dresses, sandals, sneakers, and bags). These results, summarized in Additional file 1: Fig. S2, further demonstrate the successful generalization of our class-specific diffractive imaging approach to more complex objects.
Next, we evaluated the diffractive camera’s performance with respect to the number of transmissive layers in its design (see Fig. 3 and Additional file 1: Fig. S1). Except for the number of diffractive layers, all the other hyperparameters of these camera designs were kept the same as before, for both the training and testing procedures. The patterns of the converged diffractive layers of each camera design are illustrated in Additional file 1: Fig. S3. The comparison of the class-specific imaging performance of these diffractive cameras with different numbers of trainable transmissive layers can be found in Fig. 3. Improved fidelity of the output images corresponding to the objects from the target data class can be observed as the number of diffractive layers increases, exhibiting higher image contrast, closely matching the input object features (Fig. 3a). At the same time, for the input objects from the non-target data classes, all the three diffractive camera designs generated unrecognizable noise-like patterns, all-optically erasing their information at the output. The same depth advantage can also be observed when another digit or a group of digits were selected as the target data classes. In Additional file 1: Fig. S1, we compare the diffractive camera designs with three, five, and seven successive layers and demonstrate that deeper diffractive camera designs with more layers imaged the target classes of objects with higher fidelity and contrast compared to those with fewer diffractive layers.
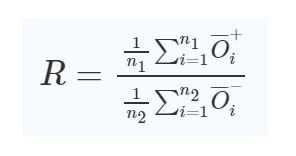
Performance advantages of deeper diffractive cameras. a Comparison of the output images using diffractive camera designs with three, four, and five layers. The output images at each row were normalized using the same constant for visualization. b Quantitative comparison of the three diffractive camera designs. The left panel compares the average PCC values calculated using input objects from the target data class only (i.e., 1032 different handwritten digits). The middle panel compares the average absolute PCC values calculated using input objects from the other data classes (i.e., 8968 different handwritten digits). The right panel plots the average output intensity ratio (R) of the target to non-target data classes
We also quantified the blind testing performance of each diffractive camera design by calculating the average PCC value between the output images and the ground truth (i.e., input objects); see Fig. 3b. For this quantitative analysis, the MNIST testing dataset was first divided into target class objects (n1= 1032 handwritten test objects for digit ‘2’) and non-target class objects (n2= 8968 handwritten test objects for all the other digits), and the average PCC value was calculated separately for each object group. For the target data class of interest, the higher PCC value presents an improved imaging fidelity. For the other, non-target data classes, however, the absolute PCC values were used as an “erasure figure-of-merit”, as the PCC values close to either 1 or −1 can indicate interpretable image information, which is undesirable for object erasure. Therefore, the average PCC values of the target class objects (n1) and the average absolute PCC values of the non-target classes of objects (n2) are presented in the first two charts in Fig. 3b. The depth advantage of the class-specific diffractive camera designs is clearly demonstrated in these results, where a deeper diffractive imager with e.g., five transmissive layers achieved (1) a better output image fidelity and a higher average PCC value for imaging the target class of objects, and (2) an improved all-optical erasure of the undesired objects (with a lower absolute PCC value) for the non-target data classes as shown in Fig. 3b.
In addition to these, a deeper diffractive camera also creates a stronger signal intensity separation between the output images of the target and non-target data classes. To quantify this signal-to-noise ratio advantage at the output FOV, we defined the average output intensity ratio (R) of the target to non-target data classes as:

where the numerator is the average output intensity of n1= 1032 test objects from the target data class (denoted as O+i), and the denominator is the average output intensity of n2= 8968 test objects from all the other data classes (denoted as O−i). The R values of three-, four-, and five-layer diffractive camera designs were found to be 1.354, 1.464, and 1.532, respectively, as summarized in Fig. 3b. These quantitative results once again confirm that a deeper diffractive camera with more trainable layers exhibits a better performance in its class-specific imaging task and achieves an improved signal-to-noise ratio at its output.
Note that, a class-specific diffractive camera trained with the standard grayscale MNIST images retains its designed functionality even when the input objects face varying illumination conditions. To demonstrate this, we first blindly tested the five-layer diffractive camera design reported in Fig. 3a under varying levels of intensity (from low to high intensity and eventually saturated, where the grayscale features of the input objects became binary). As reported in Additional file 2: Movie S1, the diffractive camera selectively images the input objects from the target class and robustly erases the information of the non-target classes of input objects, regardless of the intensity, even when the objects became saturated and structurally deformed from their grayscale features. We further blindly tested the same five-layer diffractive camera design reported in Fig. 3a with the input objects illuminated under spatially non-uniform intensity distributions, deviating from the training features. As shown in Additional file 3: Movie S2, the class-specific diffractive camera still worked as designed under non-uniform input illumination intensities, demonstrating its effectiveness and robustness in handling complex scenarios with varying lighting conditions. These input distortions highlighted in Additional file 2: Movie S1, Additional file 3: Movie S2 were never seen/used during the training phase, and illustrate the generalization performance of our diffractive camera design as an optical mode filter, performing class-specific imaging.
Simultaneous imaging of multiple objects from different data classes
In a more general scenario, multiple objects of different classes can be presented in the same input FOV. To exemplify such an imaging scenario, the input FOV of the diffractive camera was divided into 3 × 3 subregions, and a random handwritten digit/object could appear in each subregion (see e.g., Fig. 4). Based on this larger FOV with multiple input objects, a three-layer and a five-layer diffractive camera were separately designed to selectively image the whole input plane, all-optically erasing all the presented objects from the non-target data classes (Fig. 4a). The design parameters of these diffractive cameras were the same as the cameras reported in the previous subsection, except that each diffractive layer was expanded from 120 × 120 to 300 × 300 diffractive pixels to accommodate the increased input FOV. During the training phase, 48,000 MNIST handwritten digits appeared randomly at each subregion, and the handwritten digit ‘2’ was selected as our target data class to be specifically imaged. The diffractive layers of the converged camera designs are shown in Fig. 4b for the three-layer diffractive camera and in Fig. 4c for the five-layer diffractive camera.
Simultaneous imaging of multiple objects of different data classes using a diffractive camera. a Schematic and the blind testing results of a three-layer diffractive camera and a five-layer diffractive camera. The output images in each row were normalized using the same constant for visualization. b Phase modulation patterns of the converged diffractive layers for the three-layer diffractive camera design. c Phase modulation patterns of the converged diffractive layers for the five-layer diffractive camera design
During the blind testing phase of each of these diffractive cameras, the input test objects were randomly generated using the combinations of 10,000 MNIST test digits (not included in the training). Our imaging results reported in Fig. 4a reveal that these diffractive camera designs can selectively image the handwritten test objects from the target data class, while all-optically erasing the other objects from the remaining digits in the same FOV, regardless of which subregion they are located at. It is also demonstrated that, compared with the three-layer design, the deeper diffractive camera with five trained layers generated output images with improved fidelity and higher contrast for the target class of objects, as shown in Fig. 4a. At the same time, this deeper diffractive camera achieved stronger suppression of the objects from the non-target data classes, generating lower output intensities for these undesired objects.
Class-specific camera design with random object displacements over a large input field-of-view
In consideration of different imaging scenarios, where the target objects can appear at arbitrary spatial locations within a large input FOV, we further demonstrated a class-specific camera design that selectively images the input objects from a given data class within a large FOV. As the space-bandwidth product at the input (SBPi) and the output (SBPo) planes increased in this case, we used a deeper architecture with more diffractive neurons, since in general the number of trainable diffractive features in a given design needs to scale proportional to SBPi × SBPo [39, 40]. Therefore, we used seven diffractive layers, each with 300 × 300 diffractive neurons/pixels. During the training phase, 48,000 MNIST handwritten digits were randomly placed within the input FOV of the camera, one by one, and the handwritten digit ‘2’ was selected to be specifically imaged at the corresponding location on the output/image plane while the input objects from the other classes were to be erased (see the “Methods” section). As demonstrated in Additional file 4: Movie S3, test objects from the target data class (the handwritten digit ‘2’) can be faithfully imaged regardless of their varying locations, while the objects from the other data classes were all-optically erased, only yielding noisy images at the output plane. This deeper diffractive camera exhibits class-specific imaging over a larger input FOV regardless of the random displacements of the input objects. The blind testing performance shown in Additional file 4: Movie S3 can be further improved with wider and deeper diffractive camera architectures with more trainable features to better cope with the increased space-bandwidth product at the input and output fields-of-view.
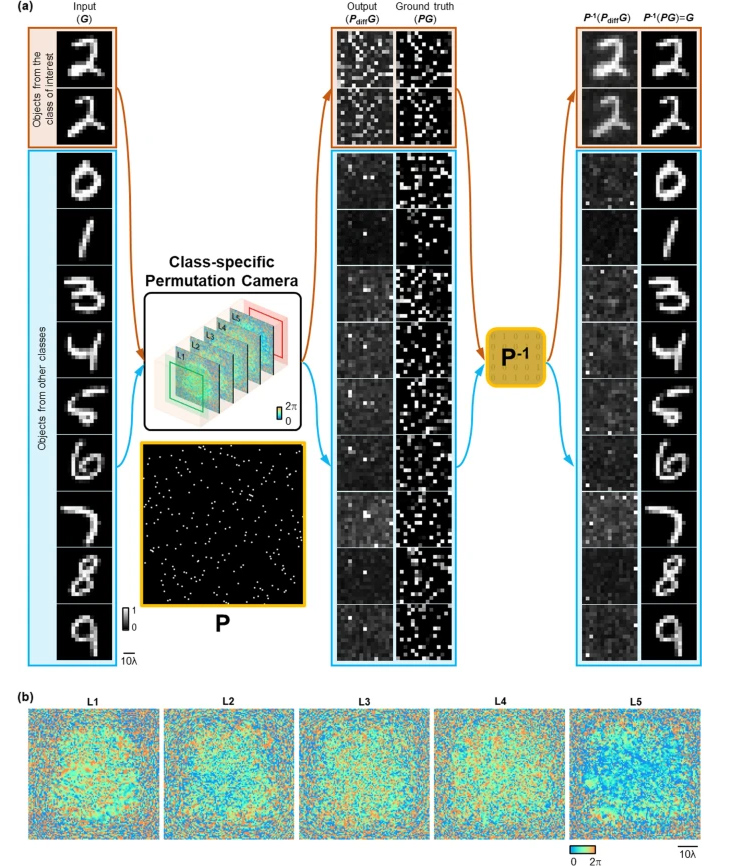
Class-specific permutation camera design
Apart from directly imaging the objects from a target data class, a class-specific diffractive camera can also be designed to output pixel-wise permuted images of target objects, while all-optically erasing other types of objects. To demonstrate this class-specific image permutation as a form of all-optical encryption, we designed a five-layer diffractive permutation camera, which takes MNIST handwritten digits as its input and performs an all-optical permutation only on the target data class (e.g., handwritten digit ‘2’). The corresponding inverse permutation operation can be sequentially applied on the pixel-wise permuted output images to recover the original handwritten digits, ‘2’. The other handwritten digits, however, will be all-optically erased, with noise-like features appearing at the output FOV, before and after the inverse permutation operation (Fig. 5a). Stated differently, the all-optical permutation of this diffractive camera operates on a specific data class, whereas the rest of the objects from other data classes are irreversibly lost/erased at the output FOV.
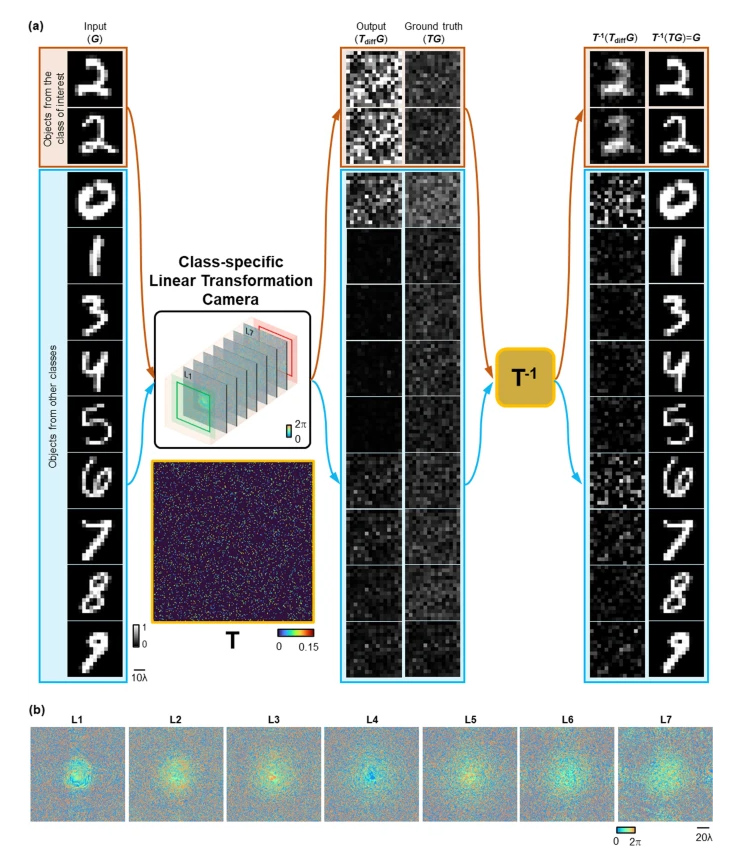
Class-specific linear transformation camera. a Illustration of a seven-layer diffractive camera trained to perform a class-specific linear transformation (denoted as TT) with instantaneous all-optical erasure of the other classes of objects at its output FOV. This class-specific all-optical linear transformation operation performed by the diffractive camera results in uninterpretable patterns of the target objects at the output FOV, which cannot be decoded without the knowledge of the transformation matrix, TT, or its inverse. By applying the inverse linear transformation (TT−1) on the output images of the diffractive camera, the original images of interest from the target data class can be faithfully reconstructed. On the other hand, the input objects from the other data classes end up in noise-like patterns both before and after applying the inverse linear transformation, demonstrating the success of this class-specific linear transformation camera design. The output images were normalized using the same constant for visualization. b Phase modulation patterns of the converged diffractive layers of the class-specific linear transformation camera
Experimental demonstration of a class-specific diffractive camera
We experimentally demonstrated the proof of concept of a class-specific diffractive camera by fabricating and assembling the diffractive layers using a 3D printer and testing it with a continuous wave source at λ= 0.75 mm (Fig. 7a). For these experiments, we trained a three-layer diffractive camera design using the same configuration as the system reported in Fig. 2, with the following changes: (1) the diffractive camera was “vaccinated” during its training phase against potential experimental misalignments [41], by introducing random displacements to the diffractive layers during the iterative training and optimization process (Fig. 7b, see the “Methods” section for details); (2) the handwritten MNIST objects were down-sampled to 15 × 15 pixels to form the 3D-fabricated input objects; (3) an additional image contrast-related penalty term was added to the training loss function to enhance the contrast of the output images from the target data class, which further improved the signal-to-noise ratio of the diffractive camera design. The resulting diffractive layers, including the pictures of the 3D-printed camera, are shown in Fig. 7b, c.
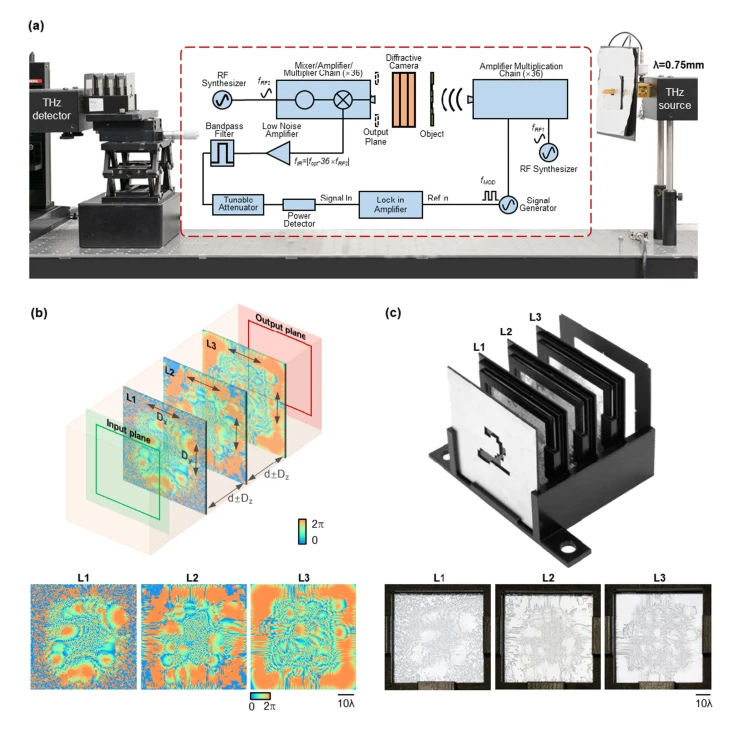
Experimental setup for object class-specific imaging using a diffractive camera. a Schematic of the experimental setup using THz illumination. b Schematic of the misalignment resilient training of the diffractive camera and the converged phase patterns. c Photographs of the 3D printed and assembled diffractive system
To blindly test the 3D-assembled diffractive camera (Fig. 7c), 12 different MNIST handwritten digits, including three digits from the target data class (digit ‘2’) and nine digits from the other data classes were used as the input test objects of the diffractive camera. The output FOV of the diffractive camera (36 × 36 mm2) was scanned using a THz detector forming the output images. The experimental imaging results of our 3D-printed diffractive camera are demonstrated in Fig. 8, together with the input test objects and the corresponding numerical simulation results for each input object. The experimental results show a high degree of agreement with the numerically expected results based on the optical forward model of our diffractive camera, and we observe that the test objects from the target data class were imaged well, while the other non-target test objects were completely erased at the output FOV of the camera. The success of these proof-of-concept experimental results further confirms the feasibility of our class-specific diffractive camera design.

Experimental results of object class-specific imaging using a 3D-printed diffractive camera
Discussion
We reported a diffractive camera design that performs class-specific imaging of target objects while instantaneously erasing other objects all-optically, which might inspire energy-efficient, task-specific and secure solutions to privacy-preserving imaging. Unlike conventional privacy-preserving imaging methods that rely on post-processing of images after their digitization, our diffractive camera design enforces privacy protection by selectively erasing the information of the non-target objects during the light propagation, which reduces the risk of recording sensitive raw image data.
To make this diffractive camera design even more resilient against potential adversarial attacks, one can monitor the illumination intensity as well as the output signal intensity and accordingly trigger the camera recording only when the output signal intensity is above a certain threshold. Based on the intensity separation that is created by the class-specific imaging performance of our diffractive camera, an intensity threshold can be determined at the output image sensor to trigger image capture only when a sufficient number of photons are received, which would eliminate the recording of any digital signature corresponding to non-target objects at the input FOV. Such an intensity threshold-based recording for class-specific imaging also eliminates unnecessary storage and transmission of image data by only digitizing the target information of interest from the desired data classes.
In addition to securing the information of the undesired objects by all-optically erasing them at the output FOV, the class-specific permutation and class-specific linear transformation camera designs reported in Figs. 5, 6 can further perform all-optical image encryption for the desired classes of objects, providing an additional layer of data security. Through the data-driven training process, the class-specific permutation camera learns to apply a randomly selected permutation operation on the target class of input objects, which can only be inverted with the knowledge of the inverse permutation operation; this class-specific permutation camera can be used to further secure the confidentiality of the images of the target data class.
Compared to the traditional digital processing-based methods, the presented diffractive camera design has the advantages of speed and resource savings since the entire non-target object erasure process is performed as the input light diffracts through a thin camera volume at the speed of light. The functionality of this diffractive camera can be enabled on demand by turning on the coherent illumination source, without the need for any additional digital computing units or an external power supply, which makes it especially beneficial for power-limited and continuously working remote systems.
It is important to emphasize that the presented diffractive camera system does not possess a traditional, spatially-invariant point-spread function. A trained diffractive camera system performs a learned, complex-valued linear transformation between the input and output fields that statistically represents the coherent imaging of the input objects from the target data class. Through the data-driven training process using examples of the input objects, this complex-valued linear transformation performed by the diffractive camera converged into an optical mode filter that, by and large, preserves the phase and amplitude distributions of the propagating modes that characteristically represent the objects of the target data class. Because of the additional penalty terms that are used to all-optically erase the undesired data classes, the same complex-valued linear transformation also acts as a modal filter, scattering out the characteristic modes that statistically represent the other types of objects that do not belong to the target data class. Therefore, each class-specific diffractive camera design results from this data-driven learning process through training examples, optimized via error backpropagation and deep learning.
Also, note that the experimental proof of concept for our diffractive camera was demonstrated using a spatially-coherent and monochromatic THz illumination source, whereas the most commonly used imaging systems in the modern digital world are designed for visible and near-infrared wavelengths, using broadband and incoherent (or partially-coherent) light. With the recent advancements in state-of-the-art nanofabrication techniques such as electron-beam lithography [42] and two-photon polymerization [43], diffractive camera designs can be scaled down to micro-scale, in proportion to the illumination wavelength in the visible spectrum, without altering their design and functionality. Furthermore, it has been demonstrated that diffractive systems can be optimized using deep learning methods to all-optically process broadband signals [44]. Therefore, nano-fabricated, compact diffractive cameras that can work in the visible and IR parts of the spectrum using partially-coherent broadband radiation from e.g., light-emitting diodes (LEDs) or an array of laser diodes would be feasible in the near future.
Methods
Forward-propagation model of a diffractive camera For a diffractive camera with N diffractive layers, the forward propagation of the optical field can be modeled as a sequence of (1) free-space propagation between the lth and (l + 1)th layers (l=0,1,2,…,N), and (2) the modulation of the optical field by the lth diffractive layer (l=1,2,…,N), where the 0th layer denotes the input/object plane and the (N + 1)th layer denotes the output/image plane. The free-space propagation of the complex field is modeled following the angular spectrum approach [45]. The optical field ul(x,y) right after the lth layer after being propagated for a distance of d can be written as [46]:
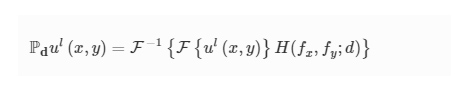
where Pd represents the free-space propagation operator, F and F−1 are the two-dimensional Fourier transform and the inverse Fourier transform operations, and H(fx,fy;d) is the transfer function of free space:
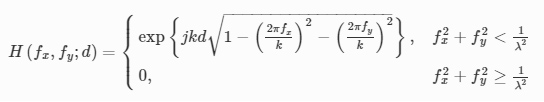
where <span class="MathJax" id="MathJax-Element-49-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">j=−1−−−√, <span class="MathJax" id="MathJax-Element-50-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">k=2πλ and <span class="MathJax" id="MathJax-Element-51-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">λ is the wavelength of the illumination light. <span class="MathJax" id="MathJax-Element-52-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">fx and <span class="MathJax" id="MathJax-Element-53-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">fy are the spatial frequencies along the <span class="MathJax" id="MathJax-Element-54-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">x and <span class="MathJax" id="MathJax-Element-55-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">y directions, respectively.
We consider only the phase modulation of the transmitted field at each layer, where the transmittance coefficient <span class="MathJax" id="MathJax-Element-56-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">tl
<span class="MathJax" id="MathJax-Element-56-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;"> of the lth diffractive layer can be written as: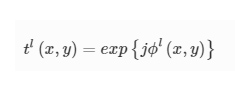
where ϕl(x,y) denotes the phase modulation of the trainable diffractive neuron located at (x,y) position of the lth diffractive layer. Based on these definitions, the complex optical field at the output plane of a diffractive camera can be expressed as:
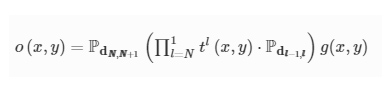
where dl−1,l represents the axial distance between the (l − 1)th and the lth layers, g(x,y) is the input optical field, which is the amplitude of the input objects (handwritten digits) used in this work.
Training loss function
The reported diffractive camera systems were optimized by minimizing the loss functions that were calculated using the intensities of the input and output images. The input and output intensities G and O, respectively, can be written as:
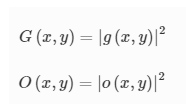
The loss function, calculated using a batch of training input objects GG with the corresponding output images OO can be defined as:
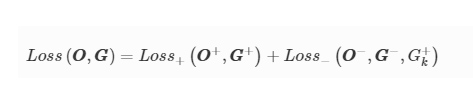
where OO+,GG+ represent the output and input images from the target data class (i.e., desired object class), and OO−,GG− represent the output and input images from the other data classes (to be all-optically erased), respectively.
The Loss+ is designed to reduce the NMSE and enhance the correlation between any target class input object O+ and its output image G+, so that the diffractive camera learns to faithfully reconstruct the objects from the target data class, i.e.,
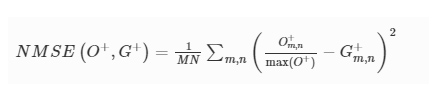
where α1 and α2 are constants and NMSE is defined as:
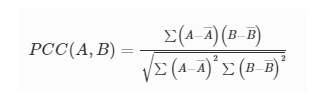
<span class="MathJax" id="MathJax-Element-79-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">m and <span class="MathJax" id="MathJax-Element-80-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">n are the pixel indices of the images, and <span class="MathJax" id="MathJax-Element-81-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">MN represents the total number of pixels in each image. The output image <span class="MathJax" id="MathJax-Element-82-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">O+ was normalized by its maximum pixel value, <span class="MathJax" id="MathJax-Element-83-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">max(O+). The PCC value between any two images <span class="MathJax" id="MathJax-Element-84-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">A and <span class="MathJax" id="MathJax-Element-85-Frame" tabindex="0" data-mathml="" role="presentation" style="box-sizing: inherit; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; position: relative;">B is calculated using [38]:
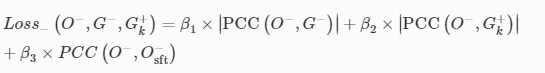
The term (1−PCC(O+,G+)) was used in Loss+ in order to maximize the correlation between O+ and G+, as well as to ensure a non-negative loss value since the PCC value of any two images is always between − 1 and 1. Different fromLoss+, the Loss− function is designed to reduce (1) the absolute correlation between the output O− and its corresponding input G−, (2) the absolute correlation between O− and an arbitrary object G+k from the target class, and (3) the correlation between O− and itself shifted by a few pixels O−sft, which can be formulated as:
where β1, β2 and β3 are constants. Here the G+k refers to an image of an object from the target data class in the training set, which was randomly selected for every training batch, and the subscript k refers to a random index. In other words, within each training batch, the PCC(O−,G+k) was calculated using the output image from the non-target data class and a random ground truth image from the target class. By adding such a loss term, we prevent the diffractive camera from converging to a solution where all the output images look like the target object. The O−sft was obtained using:
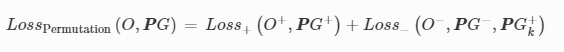
where sx=sy=5 denote the number of pixels that O− is shifted in each direction. Intuitively, a natural image will maintain a high correlation with itself, shifted by a small amount, while an image of random noise will not. By minimizing PCC(O−,O−sft), we forced the diffractive camera to generate uninterpretable noise-like output patterns for input objects that do not belong to the target data class.
The coefficients (α1,α2,β1,β2,β3) in the two loss functions were empirically set to (1, 3, 6, 3, 2).
Digital implementation and training scheme
The diffractive camera models reported in this work were trained with the standard MNIST handwritten digit dataset under λ=0.75mm illumination. Each diffractive layer has a pixel/neuron size of 0.4 mm, which only modulates the phase of the transmitted optical field. The axial distance between the input plane and the first diffractive layer, the distances between any two successive diffractive layers, and the distance between the last diffractive layer and the output plane are set to 20 mm, i.e., dl−1,l=20mm(l=1,2,…,N+1).
For the diffractive camera models that take a single MNIST image as its input (e.g., reported in Figs. 2, 3), each diffractive layer contains 120 × 120 diffractive pixels. During the training, each 28 × 28 MNIST raw image was first linearly upscaled to 90 × 90 pixels. Next, the upscaled training dataset was augmented with random image transformations, including a random rotation by an angle within [−10∘,+10∘], a random scaling by a factor within [0.9, 1.1], and a random shift in each lateral direction by an amount of [−2.13λ,+2.13λ]. For the diffractive camera model reported in Fig. 4 that takes multiplexed objects as its input, each diffractive layer contains 300 × 300 diffractive pixels. The MNIST training digits were first upscaled to 90 × 90 pixels and then randomly transformed with [−10∘,+10∘] angular rotation, [0.9, 1.1] scaling, and [−2.13λ,+2.13λ] translation. Nine different handwritten digits were randomly selected and arranged into 3 × 3 grids, generating a multiplexed input image with 270 × 270 pixels for the diffractive camera training.
For the diffractive permutation camera reported in Fig. 5, each diffractive layer contains 120 × 120 diffractive pixels. The design parameters of this class-specific permutation camera were kept the same as the five-layer diffractive camera reported in Fig. 3a, except that the handwritten digits were down-sampled to 15 × 15 pixels considering that the required computational training resources for the permutation operation increase quadratically with the total number of input image pixels. The MNIST training digits were augmented using the same random transformations as described above. The 2D permutation matrix PP was generated by randomly shuffling the rows of a 225 × 225 identity matrix. The inverse of PP was obtained by using the transpose operation, i.e., PP−1=PPTT. The training loss terms for the class-specific permutation camera remained the same as described in Eqs. (8), (9), and (12), except that the permuted input images (PPG) were used as the ground truth, i.e.,
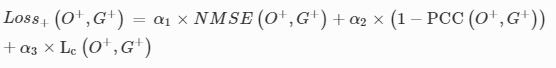
For the seven-layer diffractive linear transformation camera reported in Fig. 6, each diffractive layer contains 300 × 300 diffractive neurons, and the axial distance between any two consecutive planes was set to 45 mm (i.e., dl−1,l=20 mm, for l=1,2,…,N+1). The 2D linear transformation matrix TT was generated by randomly creating an invertible matrix with each row having 20 non-zero random entries, and normalized so that the summation of each row is 1 (for conserving energy); see Fig. 6 for the selected TT. The invertibility of TT was validated by calculating its determinant. During the training, the loss functions were applied to the diffractive camera output and the ground truth after the inverse linear transformation, i.e., TT−1O and TT−1(TTG). The other details of the training loss terms for the class-specific linear transformation camera remained the same as described in Eqs. (8), (9), and (12).
The diffractive camera trained with the Fashion MNIST dataset (reported in Additional file 1: Fig. S2) contains seven diffractive layers, each with 300 × 300 pixels/neurons. The axial distance between any two consecutive planes was set to 45 mm (i.e., dl−1,l=20 mm, for l=1,2,…,N+1). During the training, each Fashion MNIST raw image was linearly upsampled to 90 × 90 pixels and then augmented with random transformations of [−10∘,+10∘] angular rotation, [0.9, 1.1] physical scaling, and [−2.13λ,+2.13λ] lateral translation. The loss functions used for training remained the same as described in Eqs. (8), (9), and (12). The spatial displacement-agnostic diffractive camera design with the larger input FOV (reported in Additional file 4: Movie S3) contains seven diffractive layers, each with 300 × 300 pixels/neurons. The axial distance between any two consecutive planes was set to 45 mm (i.e., dl−1,l=20 mm, for l=1,2,…,N+1). During the training, each MNIST raw image was linearly upsampled to 90 × 90 pixels, and then was randomly placed within a larger input FOV of 140 × 140 pixels for training. The loss functions were the same as described in Eqs. (8), (9), and (12). The input objects distributed within a FOV of 120 × 120 pixels were demonstrated during the blind testing shown in Additional file 4: Movie S3.
The MNIST handwritten digit dataset was divided into training, validation, and testing datasets without any overlap, with each set containing 48,000, 12,000, and 10,000 images, respectively. For the diffractive camera trained with the Fashion MNIST dataset, five different classes (i.e., trousers, dresses, sandals, sneakers, and bags) were selected for the training, validation, and testing, with each set containing 24,000, 6000, and 5000 images without overlap, respectively.
The diffractive camera models reported in this paper were trained using the Adam optimizer [47] with a learning rate of 0.03. The batch size used for all the trainings was 60. All models were trained and tested using PyTorch 1.11 with a GeForce RTX 3090 graphical processing unit (NVIDIA Inc.). The typical training time for a three-layer diffractive camera (e.g., in Fig. 2) is ~ 21 h for 1000 epochs.
Experimental design
For the experimentally validated diffractive camera design shown in Fig. 7, an additional contrast loss Lc was added to Loss+ i.e.,
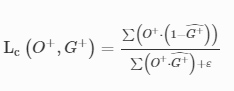
The coefficients (α1,α2,α3) were empirically set to (1, 3, 5) and Lc is defined as:
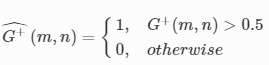
where ε=1e−6 was added to the denominator to avoid divide-by-zero error. G+ˆ is a binary mask indicating the transmissive regions of the input object G+, which is defined as:
By adding this image contrast related training loss term, the output images of the target objects exhibit enhanced contrast which is especially helpful in non-ideal experimental conditions.
In addition, the MNIST training images were first linearly downsampled to 15 × 15 pixels and then upscaled to 90 × 90 pixels using nearest-neighbor interpolation. Then, the resulting input objects were augmented using the same parameters as described before and were fed into the diffractive camera for training. Each diffractive layer had 120 × 120 trainable diffractive neurons.
To overcome the challenges posed by the fabrication inaccuracies and mechanical misalignments during the experimental validation of the diffractive camera, we vaccinated our diffractive model during the training by deliberately introducing random displacements to the diffractive layers [41]. During the training process, a 3D displacement DD=(Dx,Dy,Dz) was randomly added to each diffractive layer following the uniform (U) random distribution: